巷では「ArrayBlockingQueue よりも LinkedBlockingQueue の方がスループット性能がいいよ」なんてまことしやかに言われているけど、どうにも気になったので検証してみたら、実は ArrayBlockingQueue の方が性能いいんじゃない? という結論に至った話です。
Producer-Consumer デザインパターンと BlockingQueue
Java で Producer-Consumer デザインパターン を実現するときによくお世話になる BlockingQueue インタフェース。このインタフェースには ArrayBlockingQueue クラス と LinkedBlockingQueue クラス の二つの実装が標準 API として提供されています。
高い処理性能を要求されるプログラムを Java で書こうとしたときに、CPU のすべてのコアをフル稼動させることを狙って Producer-Consumer パターンによって処理フローをパイプライン的に構成することがあります。そのときにいつも気になっていたのが、「ArrayBlockingQueue と LinkedBlockingQueue、果たしてどちらを利用した方がスループットが高くなるのだろうか?」ということ。
この疑問に対して、海外でも 議論 されていたり、検証 されていたりされているようで、それらの 結論 としては概ね「LinkedBlockingQueue の方が ArrayBlockingQueue よりも高スループットだよ」というものになっています。
しかし、ArrayBlockingQueue と LinkedBlockingQueue の双方の実装やデータ構造の特性を考えると「LinkedBlockingQueue の方が高スループット」という結論がにわかに信じ難かったので、実際に検証をしてみることにしました。
双方のデータ構造と実装の特性
検証を始める前にまず、それぞれのデータ構造および実装の特性を確認してみることにします。参考にした実装は Oracle の JDK 1.7 (update 17) です。
ArrayBlockingQueue クラス
- 配列をベースとしたキュー実装で、配列をリングバッファとして扱います。
- エンキュー (add() / offer() / put()) 操作、デキュー (remove() / poll() / take()) 操作をする配列上のインデックスを、それぞれ別々に保持しています (putIndex フィールドと takeIndex フィールド)。
- キューの大きさは固定長で、その大きさを超える要素数を保持することはできません。
- エンキュー操作において、余計なオブジェクトが生成されることはありません。
- エンキュー/デキュー操作では、一つのロックオブジェクト (lock フィールドの ReentrantLock オブジェクト) を共用して排他制御をします。
- エンキューとデキュー操作のメソッド呼び出しが重なると、一方の処理にてロック解除待ちが生じてしまいます。
LinkedBlockingQueue クラス
- 片方向の連結リストをベースとしたキュー実装です。
- 連結リストの先頭 (head フィールド) より要素をデキューし、末尾 (last フィールド) に要素をエンキューします。
- 保持できる要素数は最大で Integer.MAX_VALUE になります。
- コンストラクタで capacity を指定することで、保持する要素数を制限することもできます。
- 要素のエンキュー操作ごとに、連結リストの Node オブジェクトの生成操作が発生します。
- 1 つの要素につき 16 バイトほどのヒープを余計に消費します。
- エンキュー/デキュー操作の排他制御はそれぞれ別々のロックオブジェクト (putLock フィールド、takeLock フィールド) を利用します。
- エンキューとデキュー操作のメソッド呼び出しが重なったとしても、ロック解除待ちは発生せず並列に処理することができます。
これら上記の双方の特性を比較すると、
- ArrayBlockingQueue は処理が単純な分、エンキュー/デキュー操作の処理コストが小さく、一方で LinkedBlockingQueue はオブジェクト生成が必要となるために特にエンキュー操作の処理コストが高い。
- ArrayBlockingQueue は、エンキュー/デキュー操作においてロックオブジェクトを共有するために Producer / Consumer の並列性が低くなるが、LinkedBlockingQueue は別々のロックオブジェクトが用意されているため、Producer / Consumer の並列性が高まる。
と言うことができそうです。 LinkedBlockingQueue の方がスループットが高い、というのは後者の並列性が根拠になっていると思われますね。
性能検証する
続いて、実際に両者の BlockingQueue 実装を利用したプログラムを作成し、各種性能を測定してみました。
測定方法
検証用プログラム を用いて、エンキュー操作、デキュー操作を独立して 1,600 万回ほど行ったときの処理時間、およびエンキュー/デキュー操作を複数の別スレッド (Producer / Consumer) で同時並列に 1,600 万回実施したときのスループットを ArrayBlockingQueue, LinkedBlockingQueue それぞれの実装ごとに測定してみました。
また測定を進めていく上で、Java VM の 32 bit と 64 bit の違いや、Java コンパイラ (JDK / Eclipse)、ハードウェア・OS (Windows / Mac) の違いが性能に影響を与えることが明らかになったため、これらの構成の組み合わせも合わせて検証してみることにしました。
検証環境
- ハードウェア・OS
- Windows PC
- Windows 7 (64 bit)
- Core i5-3450 (3.10GHz)
- 8GB Memory
- Mac
- Mac OS X 10.8.2
- 1.7GHz Core i5-3317U
- 4GB Memory
- Java
- Java VM (オプション : Xms1200m)
- Java 7 Update 17 (32 bit & 64 bit)
- Java コンパイラ
- JDK 1.7 Update 17
- Eclipse Compiler for Java 3.8.2
測定項目
- エンキュー/デキュー操作を行う各種メソッドの呼び出しにかかる時間 [ミリ秒]
- スループット [メッセージ/秒]
- Producer x 1 スレッド, Consumer x 1 スレッド
- Producer x 1 スレッド, Consumer x 2 スレッド
- Producer x 2 スレッド, Consumer x 1 スレッド
- Producer x 2 スレッド, Consumer x 2 スレッド
測定結果と考察
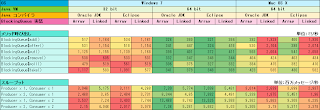
上記の内容で測定した結果を Google ドキュメントで公開 しています。数値に対するカラースケールは行(横一列)のグループに対して設定されており、緑色が良い性能であることを、黄色がほどほどの性能を、赤色が性能が悪いことを示します。
Java VM (64 bit / 32 bit) の違い
さてこの結果を見てすぐに分かることは、ArrayBlockingQueue と LinkedBlockingQueue のどちらについても、32 bit Java VM よりも 64 bit の方が性能がよい、ということになりますね。メソッド単体の呼び出し性能もスループットも、どちらも下は 1.5x から上は 4x ぐらいまでの性能が 64 bit VM では出ています。
メソッドの呼び出し性能に着目すると、32 bit VM ではメソッド間で性能差が大きく開きバラつきがあり、ArrayBlockingQueue も LinkedBlockingQueue もそれぞれの性能特徴がよく分かる結果となっています。一方で 64 bit VM では、メソッド間の性能差は 32 bit ほどの開きは見られず、安定した性能が出せていることがうかがえます。
スループットについては、64 bit VM を使うことで ArrayBlockingQueue の性能が 32 bit VM のときより大幅に性能向上することが見て取れます。LinkedBlockingQueue も 64 bit VM による性能劣化はなく、ArrayBlockingQueue ほどではないものの多少の性能向上がうかがえます。
Java VM の違いにおいて ArrayBlockingQueue と LinkedBlockingQueue の結果を比較すると、
- 32 bit VM では LinkedBlockingQueue の方が性能がよい。
- 64 bit VM では ArrayBlockingQueue の方が性能がよい。
と言えるでしょう。
Java コンパイラ (JDK / Eclipse) の違い
コンパイラの違いについては、今回の測定結果では優劣が明確になるほどの性能差は出ませんでした。
ハードウェア・OS の違い
Mac の場合、ArrayBlockingQueue と比べて LinkedBlockingQueue の性能が全体的に悪いことがわかります。メソッドの呼び出しについては、特にエンキュー操作の性能が極端に悪いですね。
スループットも、エンキュー操作メソッドの性能に引きづられてか、LinkedBlockingQueue の性能は芳しくありません。エンキュー操作が競合しやすい Producer x 2 の構成での落ち込みが大きいですね。
Mac では、 ArrayBlockingQueue 択一 と言ってしまっていいと思います。
まとめ
ArrayBlockingQueue を使うべきか、それとも LinkedBlockingQueue を使うべきかの判断は Java VM 次第、すなわち
- (Mac を含む) 64 bit の Java VM を利用するなら ArrayBlockingQueue がよい。
- 32 bit の Java VM なら LinkedBlockingQueue がよい。
と言ってしまっていいでしょう。ただ今後のことを考えれば 64 bit VM の利用が多くなっていくと考えられるため、開発時点では 32 bit の VM 利用を想定していても、ArrayBlockingQueue を採用しておくのが無難じゃないかと思います。はい。
だいじなこと
今回は Windows と Mac とで性能検証をしてきたのですが、実際に Java アプリが利用される環境は Linux など Unix 系の OS が多いかと思います。今回の検証でなんとなく傾向はつかめた (64 bit なら ArrayBlockingQueue) のですが、これがそのまま Linux でも通じるかどうかはまた別の話、つまりは要検証、ということです。






